On scheduling algorithms and daily decisions
Context
I recently spent time measuring system call costs and context switch overhead. The exercise forced me to think about how schedulers optimize for competing metrics: turnaround time versus response time, throughput versus fairness. What surprised me was how directly these tradeoffs map to how I structure my days.
The scheduling problem in life
Operating systems face a fundamental challenge: tasks arrive unpredictably, their durations are unknown, and the scheduler must balance multiple objectives without perfect information. They simply do not know how long the process is going to last. This is exactly the position I find myself in every day.
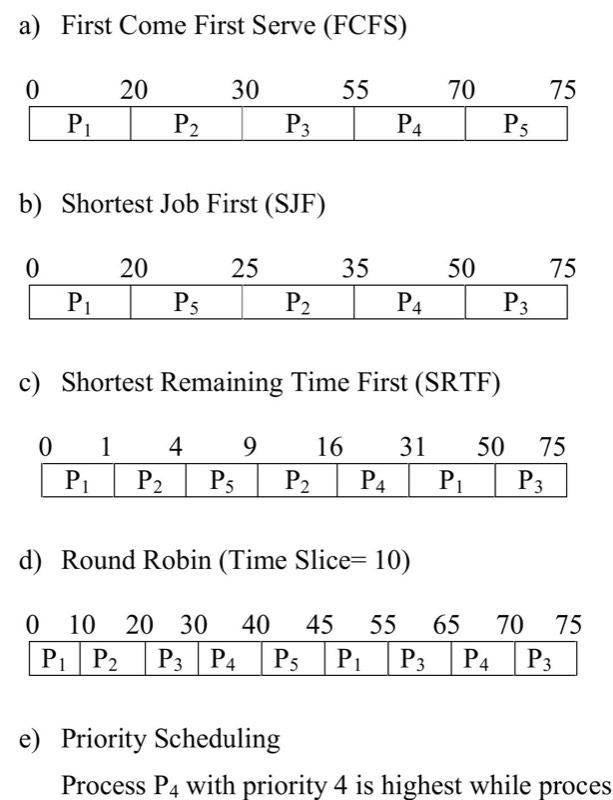
First In, First Out works until it doesn’t. The moment a long task arrives first, everything else waits. I’ve experienced this: spending hours on something that felt urgent (but wasn’t important) while truly time-sensitive work queued behind it. The convoy effect is real.
Shortest Job First requires knowing task lengths upfront. I don’t. My time estimates are consistently optimistic by a factor of 2-3x. But the principle is useful: when I actually identify quick wins, clearing them creates momentum.
Context switching costs
I measured context switch times using pipes between processes. Two key findings:
- Switching between tasks takes measurable time (not just the work itself)
- This overhead compounds with frequency
In practice, this means:
- Checking Slack mid-task destroys state
- “Just quickly” doing something else has hidden costs
- Round Robin sounds fair but can mean nothing finishes
I measured my own context switching informally. After about 2-3 interruptions, I lose the mental model of what I was doing. Recovery takes 25-30 minutes. The overhead is significant.
Response time versus turnaround time
Schedulers optimize for different metrics:
- Turnaround time: How long from arrival to completion
- Response time: How long until first scheduled
These are often in conflict. Round Robin gives excellent response time (everything gets touched quickly) but poor turnaround time (nothing finishes fast). FIFO is the opposite.
I notice this tradeoff daily. Responding quickly to everything feels productive but delays completion of substantial work. Ignoring interruptions improves turnaround but damages responsiveness to time-sensitive requests.
There’s no optimal solution. The right balance depends on the workload.
Learning from MLFQ: How a Scheduling Algorithm Reshaped My Approach to Time
Multi-Level Feedback Queue learns from observed behavior. Tasks start at high priority. If they use their full time slice, priority decreases. If they yield early (like I/O-bound processes), they stay high.
The insight: the scheduler doesn’t need perfect knowledge upfront. It adapts based on what actually happens.
Applied to tasks:
- New items start with benefit of the doubt
- Long-running work proves itself over time and gets scheduled differently
- Interactive tasks that need quick responses stay high priority
- Adjustments happen continuously, not once at planning time
This feels more realistic than trying to perfectly estimate everything upfront.
Practical changes that I took to integrate the idea of Multi-Level Feedback Queue in my own life
- Dedicate uninterrupted blocks to deep work, treating my attention as a precious resource
- Group similar small tasks into focused “processing windows” to maintain mental momentum
- Consciously decide each morning: Am I optimizing for depth or breadth today?
- Recognize that not every interesting opportunity deserves immediate attention
- Track my actual energy and focus costs when switching between different types of work